Title here
Summary here
June 21, 2023 作者 nevstop1 分钟
本文整理自知乎回答,并按站点文档风格进行结构化排版。 原文链接
当 PLC 变量数量上升到几千点时,很多“小系统里还凑合”的做法会迅速失效。原回答里给出的是一套偏工程化的落地思路,重点不是单个驱动 API 怎么调用,而是如何把海量变量的连接、调度、展示和告警拆成可维护的层次。
这套方案面对的是“大量 PLC 点位 + 实时刷新 + 长时间稳定运行”的组合场景。原回答给出的实测规模是:
在这个量级下,核心问题通常不再是“能不能读到数据”,而是“如何长期稳定、可维护地读到数据”。
原回答把方案拆成 5 个关键点:
Datasocket 进行 PLC 变量通讯,而不是直接依赖网络共享变量绑定。这几条放在一起看,实际上是在回答一个更大的问题:如何让“PLC 接入”不把整个应用拖成一团。
原回答的第一条就明确绕开了网络共享变量绑定,这背后的取舍很清楚:点位一多,直接绑定虽然上手快,但后续在分组调度、重连控制、异常隔离和配置管理上都会变得比较被动。
改成 Datasocket + 自己的调度层之后,系统可以更明确地控制:
当变量规模到几千点时,配置不可能靠手工散落在 block diagram 里维护。原回答采用 Excel 来管理:
它的价值不是“Excel 方便编辑”这么简单,而是把通讯配置从程序逻辑里抽离出来,让批量调整、导入和核对都更容易做。
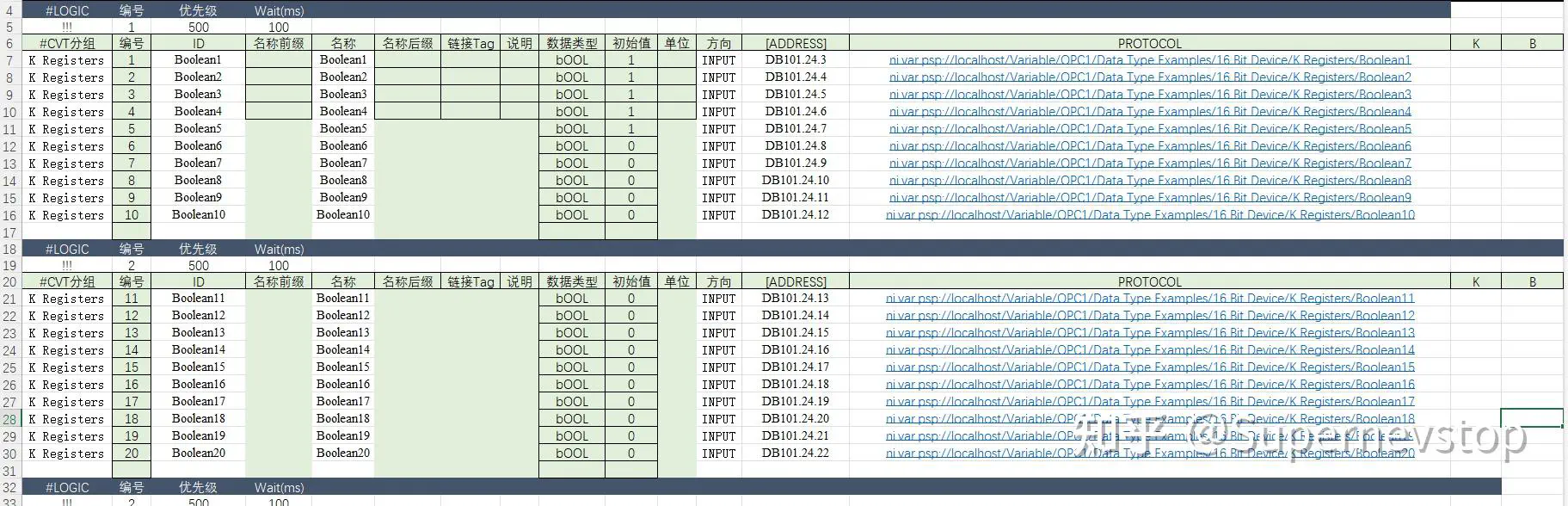
每个分组独立循环运行,循环内部再用状态机处理读写和异常,是这套方案能扩展到更大规模的关键。
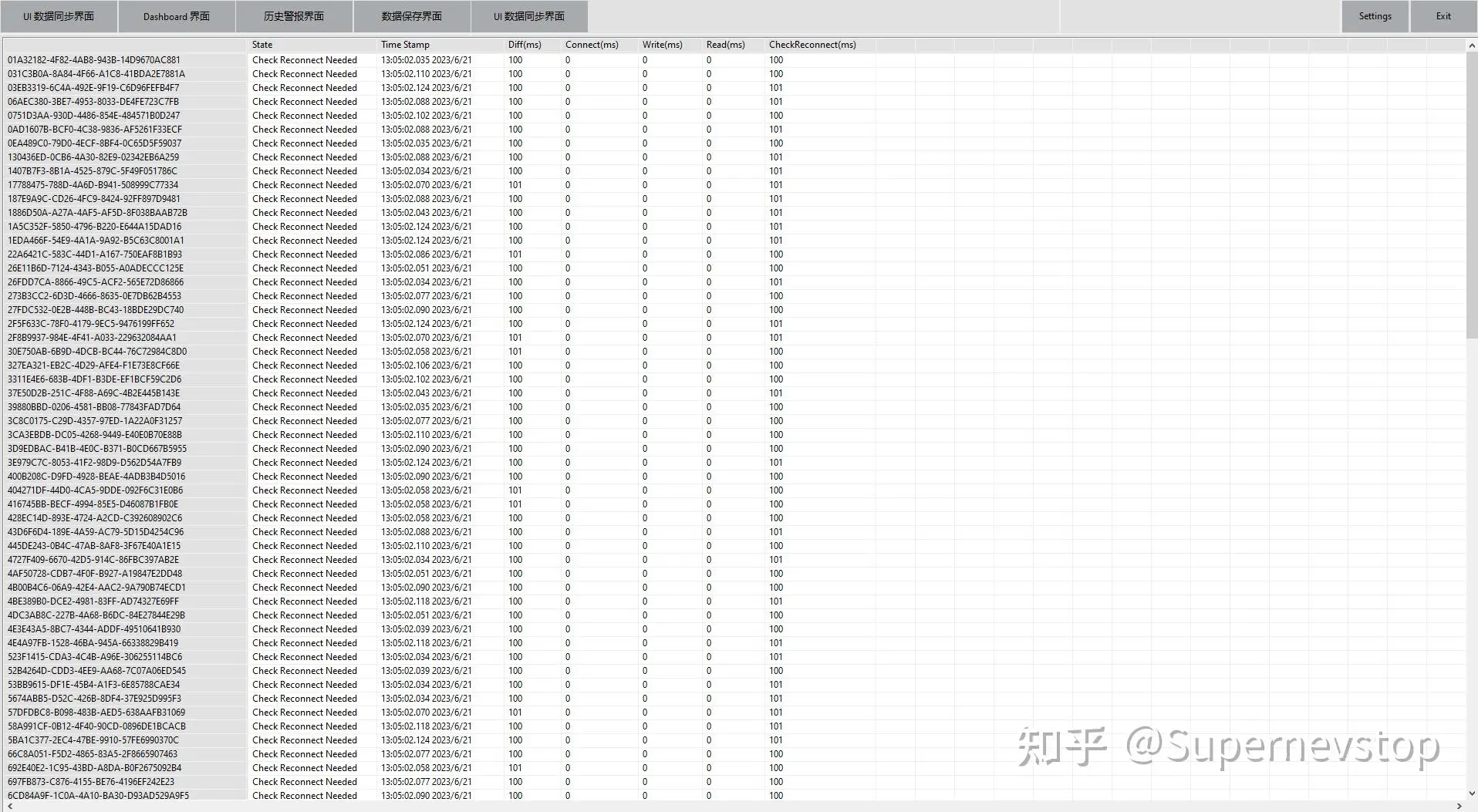
原回答特别提到一个细节:如果某个分组里有异常 PLC 变量,需要做的是只重连异常变量,而不是整套系统一起重连。这个边界一旦划清,系统在局部故障下的稳定性会明显提高。
原回答中另一个值得保留的点,是“所有数据架设数据中间层”。也就是:
这会让后续扩展变得容易很多,比如新增历史记录、报警策略、报表导出时,不需要反复回到 PLC 通讯循环里改逻辑。
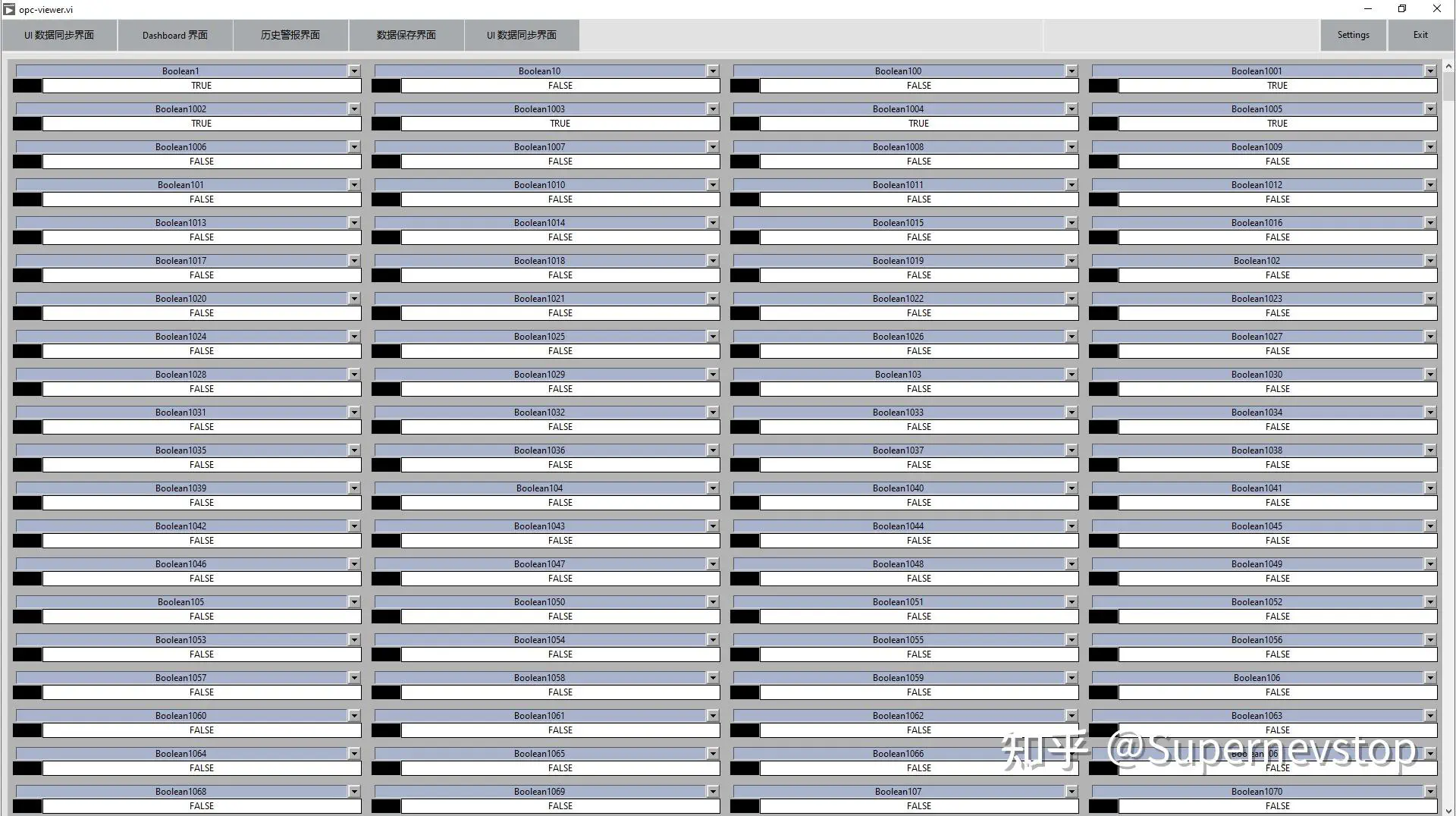
在界面层,原回答采用 VIScript 自动同步前面板控件和数据中间层,只要控件 ID 与数据 ID 对应即可。这种做法对大量变量场景很重要,因为它能减少大量手工绑定和重复界面代码。
原回答最后也明确说明,这套系统当时还在继续打磨中,后续还要做的包括:
这点很重要,因为它说明这不是一个“理论架构图”,而是一个已经跑过真实规模、但仍在继续工程化的方案。
面对成千上万的 PLC 变量,真正有效的通常不是某一个更快的读写 VI,而是一整套分层方法:配置层、调度层、数据中间层和界面层各自分责,局部异常局部恢复。原回答里这套 2500+ 点位方案的价值,正在于它把这些边界划清了。